推荐中的特征交叉技术
特征交叉范式
特征交叉指的是通过组合两个(或多个)特征来学习特征间非线性的组合高阶表达,其收益则是来自通过挖掘特征之间的共现组合,拓展了特征输入的表达,从而使得模型能更容易学习到共现组合提供的信息。 业界实现方案可以主要分为非参数化方案和参数化方案。
非参数化方案:显式的表达特征交叉ID,例如特征求交,笛卡尔积特征等。
参数化方案:主要通过模型参数隐式拟合的形式去捕捉特征的非线性组合能力,而参数化方案在DNN基础上的创新迭代又主要分为以下两类范式:
- 范式一:通过模型参数拟合的过程中, 能够明确特征的交互关系,例如DeepFM,PNN,以及CAN。
- 范式二:无法明确特征具体交互关系,通过设计更复杂的后端网络追求特征的implict组合和高阶融合,例如DCN,xDeepFM,FIBNET等
需要注意的是,两种范式并不冲突,如果我们将范式一定义丰富输入X的表达,则范式二则是在复杂化F表达式,那么两者结合的F(X)可能会带来进一步收益.
方法
非参数化
即人为的将不同的特征进行组合表达,提高输入到模型的信息量,从而促使模型的效果更好。如图所示:
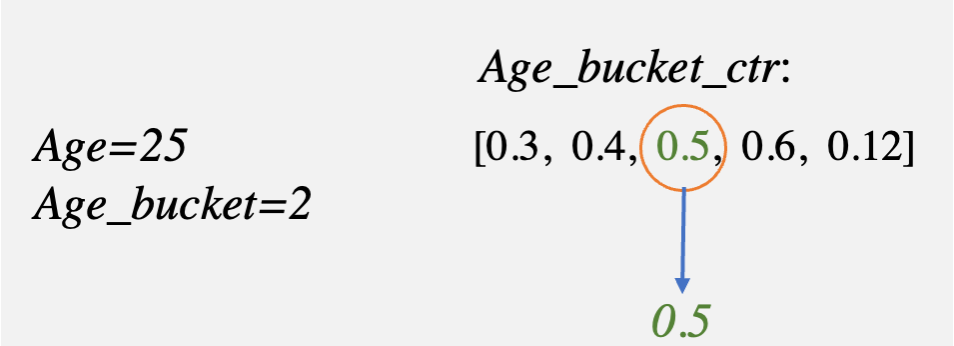
参数化方法
FM
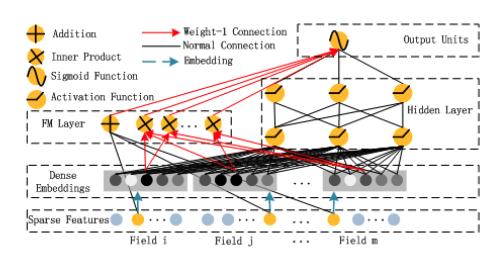
\begin{equation} \begin{aligned}y=w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^n\sum_{j=i+1}^n\langle v_i,v_j\rangle x_ix_j\end{aligned} \end{equation}
PNN
PNN,全称为$Product-based\ Neural\ Network$,认为在embedding输入到MLP之后学习的交叉特征表达并不充分,提出了一种product layer的思想,即基于乘法的运算来体现特征交叉的DNN网络结构。
PNN模型大致由三个部分组成:embedding层、product层、FC层。
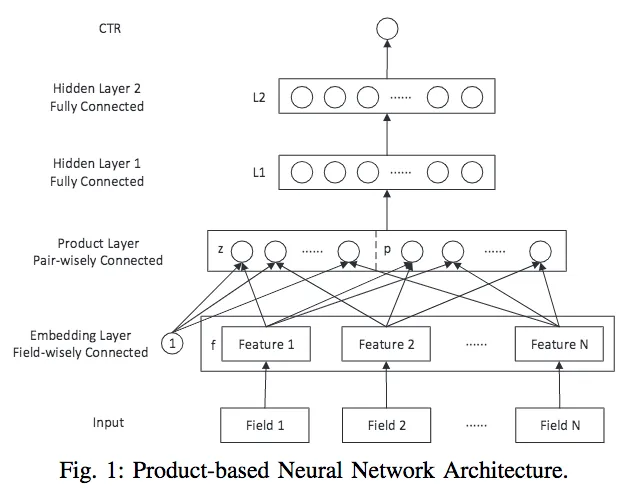
根据交叉函数g的不同,PNN可分为IPNN和OPNN。这里主要介绍IPNN: $$ \begin{equation} \begin{aligned} \boldsymbol{z}=\begin{pmatrix}\boldsymbol{z}_1,\boldsymbol{z}_2,\ldots,\boldsymbol{z}_N\end{pmatrix}\triangleq\begin{pmatrix}\boldsymbol{f}_1,\boldsymbol{f}_2,\ldots, \boldsymbol{f}_N\end{pmatrix} \end{aligned} \end{equation} $$ $$ \boldsymbol{p}=\{\boldsymbol{p}_{i,j}\}, i=1…N, j=1…N $$
$$ \begin{equation} \begin{aligned} \boldsymbol{l}_{z}=\left(l_{z}^{1},l_{z}^{2},\ldots,l_{z}^{n},\ldots,l_{z}^{D_{1}}\right),\quad l_{z}^{n}=\boldsymbol{W}_{z}^{n}\odot\boldsymbol{z} \\ \end{aligned} \end{equation} $$
$$ \begin{equation} \begin{aligned} &\boldsymbol{l}_{p}=\left(l_{p}^{1},l_{p}^{2},\ldots,l_{p}^{n},\ldots,l_{p}^{D_{1}}\right),\quad l_{p}^{n}=\boldsymbol{W}_{p}^{n}\odot\boldsymbol{p} \\ \end{aligned} \end{equation} $$
$$ \boldsymbol{l}_1=\mathrm{relu}(\boldsymbol{l}_z+\boldsymbol{l}_p+\boldsymbol{b}_1) $$
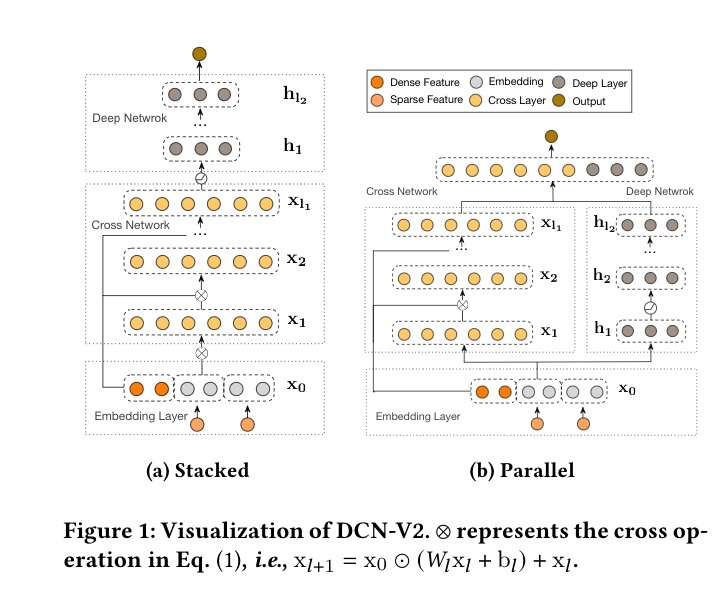
DCN
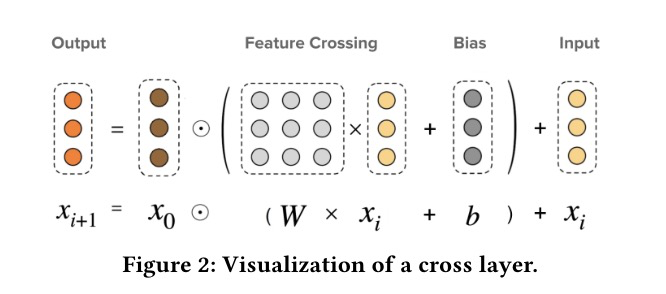
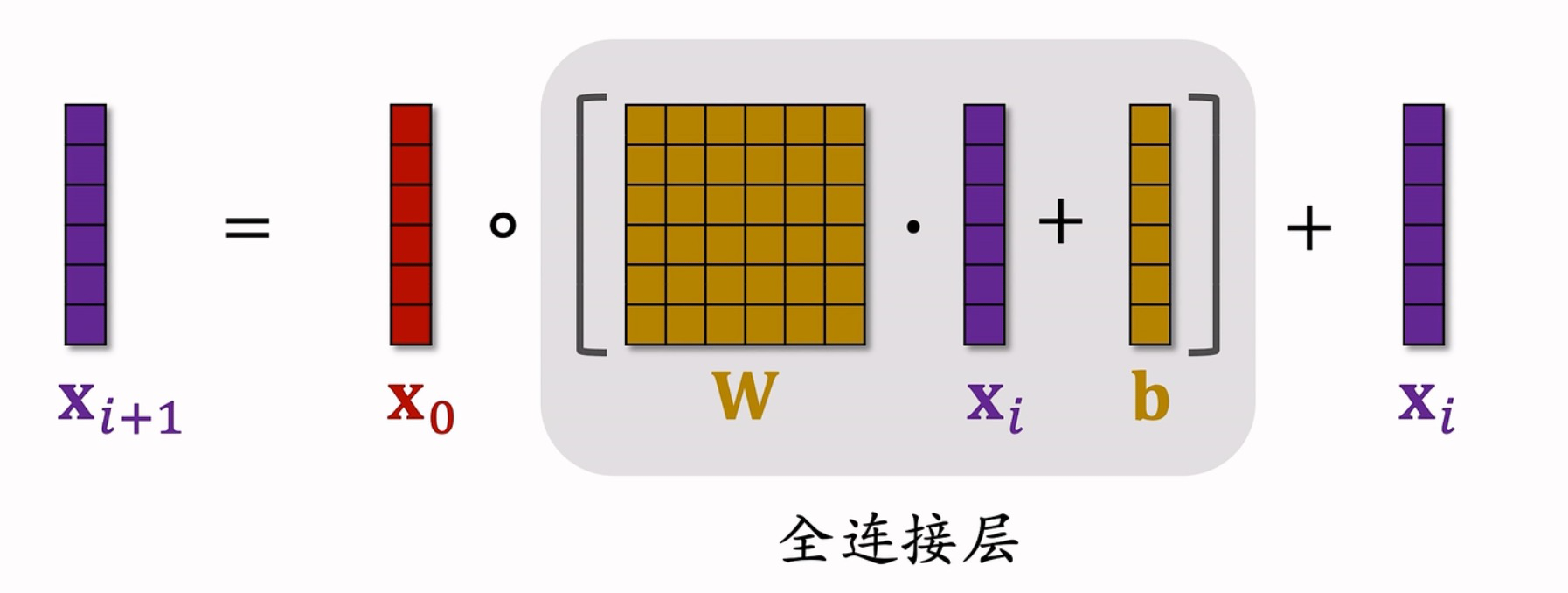
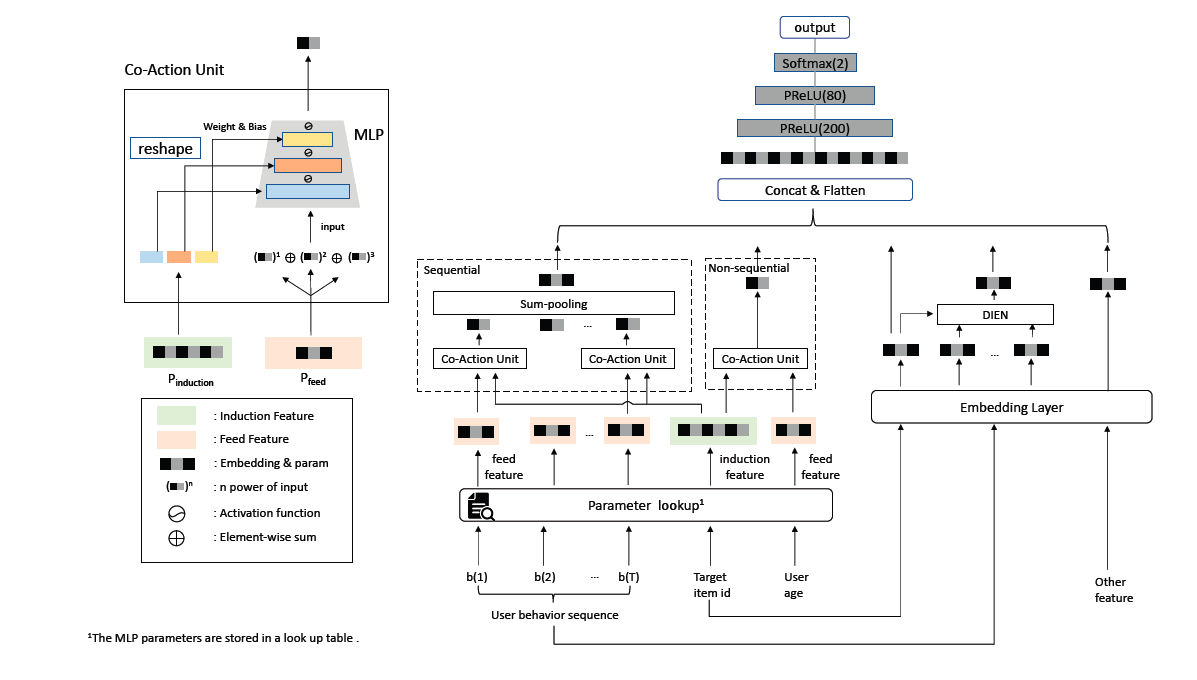
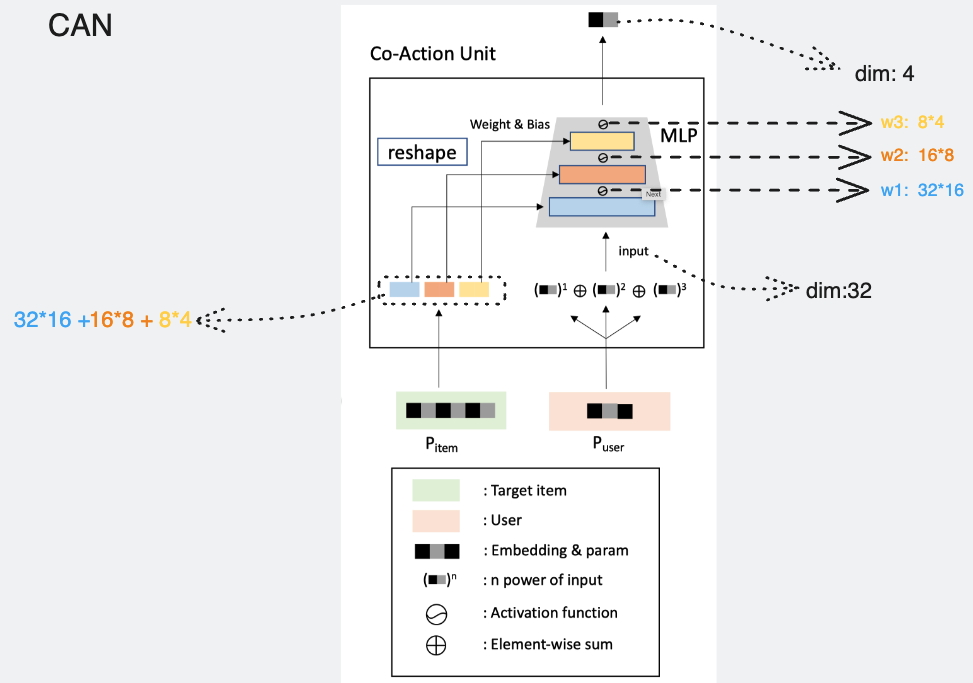
CAN
关于作者最后一部分提到的多层次独立性$multi-level\ Independence$
-
参数独立:必须使用。即每个特征都有两种初始的向量,一种是用于表征学习的,即前文提到的$e_{user}$; 一种是用于co-action建模的,即前文提到的$p_{user}$ 。这两个参数是独立的。这一点实际上对我是有启发的。在日常使用DIN的过程中,我发现每个item本身的嵌入和在序列中的嵌入独立开,会比二者共享同一个嵌入的效果更好。可能是因为通过参数独立,可以更好地建模种记忆性的场景。还比如,目标item和序列item直接做笛卡尔积,即:目标item & 序列item1,目标item & 序列item2,依次类推,每一个交叉特征整体都单独作嵌入,这种方式在强记忆性场景也是有效的。
-
组合独立:推荐使用。前文我们提到,item(参数侧)的特征,会和多种user(输入侧)的特征做co-action建模,这样item是会被共享的,可能会影响学习的独立性。一种思路是,同一个item,对每个不同的user侧特征,用于建模其co-action的item侧特征参数都不一样;user侧同理。这种情况下,如果有N个user特征,M个item特征,那么item侧需要$O(M×N×T)$的参数量,user侧需要$O(M×N×D)$的参数量。这种方式的参数量和笛卡尔积是相同的,并没有降低参数量。那么其优势只剩下CAN Unit结构本身了。
-
阶数独立:可选。针对上述user端特征多阶提升做的独立性。即:不同阶对应不同的$MLP_{can}$网络参数。
Reference
- DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- Product-based neural networks for user response prediction
- CAN: Feature Co-Action Network for Click-Through Rate Prediction
- [广告机制]-模型篇:CTR预估之PNN算法
- 想为特征交互走一条新的路
- 特征交互新思路| 阿里 Co-action Network论文解读