Flink 流处理API
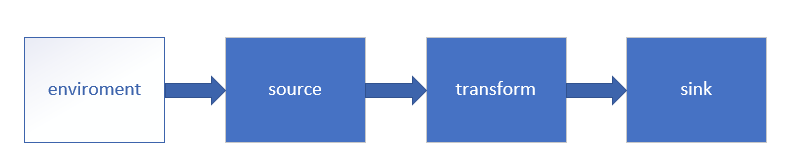
1. Environment
1.1 getExecutionEnvironment
创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说,getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
1.2 createLocalEnvironment
1 | LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1); |
1.3 createRemoteEnvironment
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("jobmanage-hostname", 6123,"YOURPATH//WordCount.jar"); |
2. Source
2.1 集合
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
2.2 文件
1 | String path = "src/main/resources/sensor.txt"; |
2.3 kafka消息队列
1 | Properties properties = new Properties(); |
2.4 自定义Source
除了以上的source数据来源,我们还可以自定义source。需要做的,只是传入一个SourceFunction就可以。具体调用如下:
1 | DataStreamSource<SensorReading> dataStream = env.addSource(new MySourceFucntion()); |
我们希望可以随机生成传感器数据,MySensorSource具体的代码实现如下:
1 | public static class MySourceFucntion implements SourceFunction<SensorReading>{ |
3. Transform
3.1 map

1 | DataStreamSource<String> inputStream = env.readTextFile(path); |
3.2 flatMap
1 | // 2. flatmap,按逗号分字段 |
3.3 filter

1 | DataStream<String> filterStream = inputStream.filter(line -> line.startsWith("sensor_1")); |
3.4 keyBy
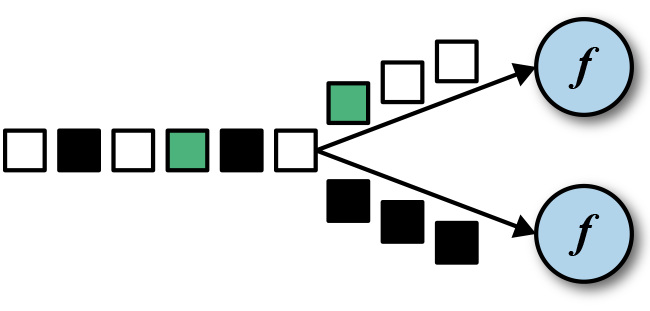
DataStream→KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的.
3.5 滚动聚合算子(Rolling Aggregation)
这些算子可以针对$KeyedStream$的每一个支流做聚合。
- sum()
- min()
- max()
- minBy()
- Maxby()
3.6 Reduce
KeyedStream →DataStream:一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
1 | DataStreamSource<String> inputStream = env.readTextFile(path); |
3.7 Split/Select
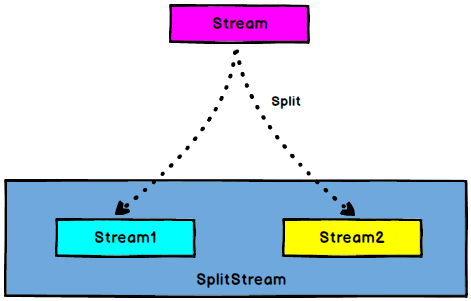
DataStream → SplitStream:根据某些特征把一个$DataStream$拆分成两个或者多个$DataStream$.
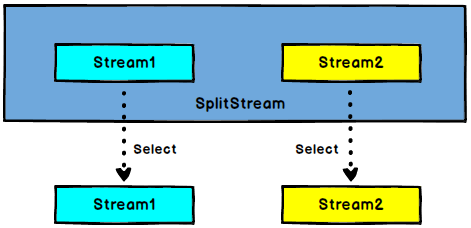
SplitStream→DataStream:从一个SplitStream中获取一个或者多个DataStream.
1 | //传感器数据按照温度高低(以 30 度为界),拆分 成两个流 。 |
3.8 Connect和CoMap
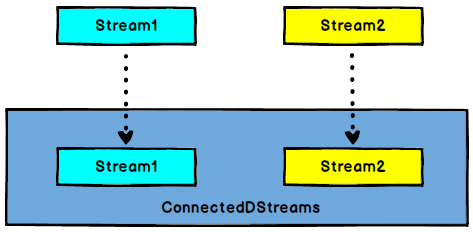
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
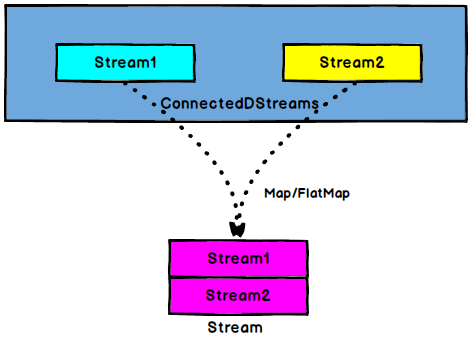
ConnectedStreams → DataStream:作用于$ConnectedStreams$上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理
1 | // 2. 合流 connect,将高温流转换成二元组类型,与低温流连接合并之后,输出状态信息 |
3.9 Union
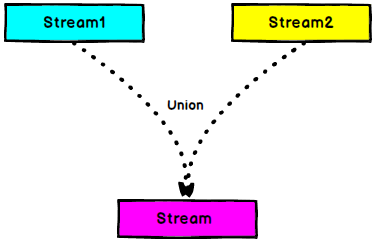
DataStream → DataStream:对两个或者两个以上的$DataStream$进行union操作,产生一个包含所有$DataStream$元素的新$DataStream$。
Union之前两个流的类型必须是一样,Connect可以不一样,在之后的coMap中再去调整成为一样的。
Connect只能操作两个流,Union可以操作多个
1 | highStream.union(lowStream, allStream); |
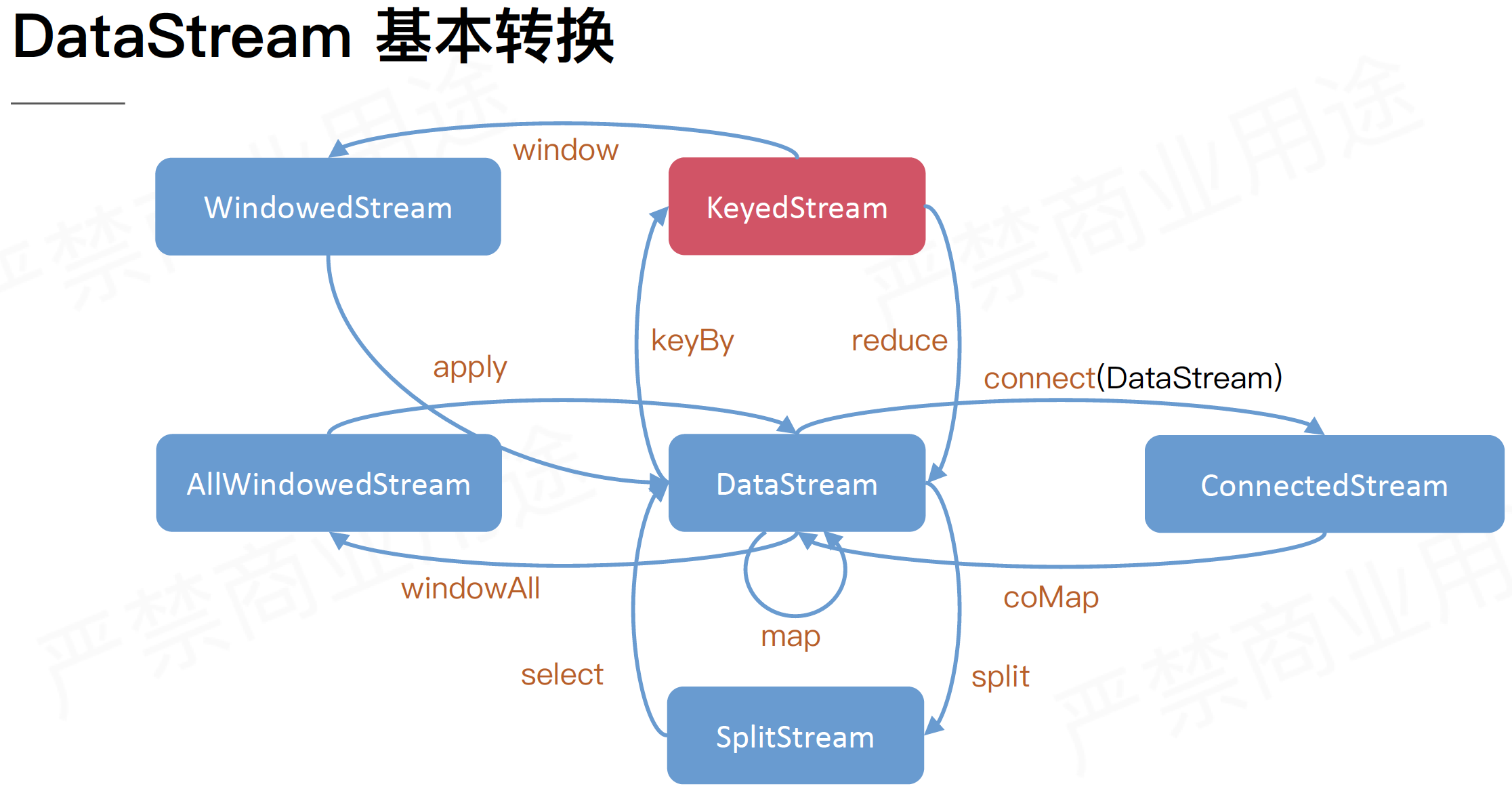
总览