$Nested-Loop\ Join$
$MySql$只支持一种join算法:$Nested-Loop Join$(嵌套循环连接),但$Nested-Loop\ Join$有三种变种:$Simple\ Nested-Loop\ Join,Index\ Nested-Loop\ Join,Block\ Nested-Loop Join$(简单-索引-缓冲区)
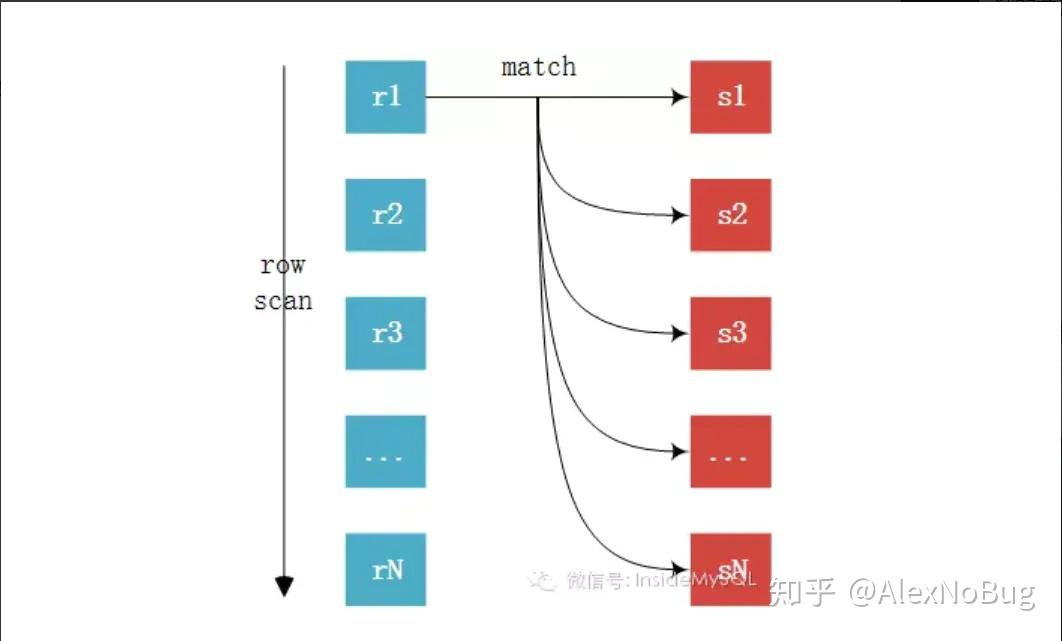
$Simple\ Nested-Loop\ Join:$
如图,$R$为驱动表,$S$为匹配表,可以看到从r中分别取出$r_1、r_2、……、r_n$去匹配$S$表的左右列,然后再合并数据,对$S$表进行了$r*n$次访问,对数据库开销大:
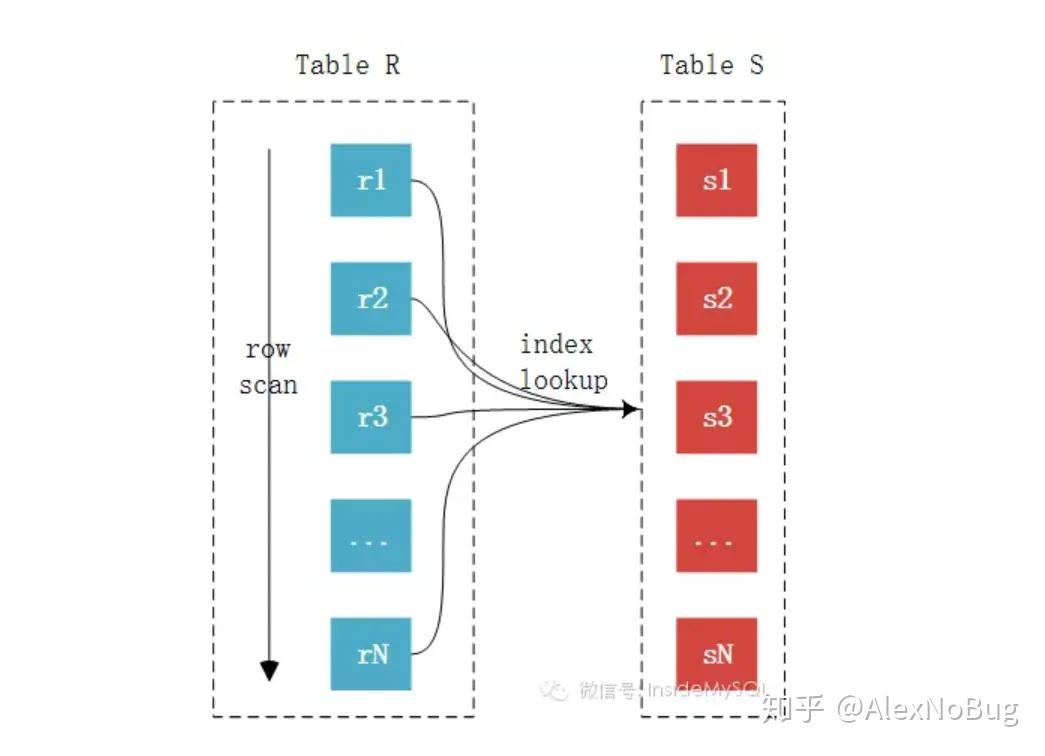
$Index\ Nested-Loop\ Join$(索引嵌套):
在查询时,如果被驱动表$S$的关联字段是有索引的,那么查询就要快很多
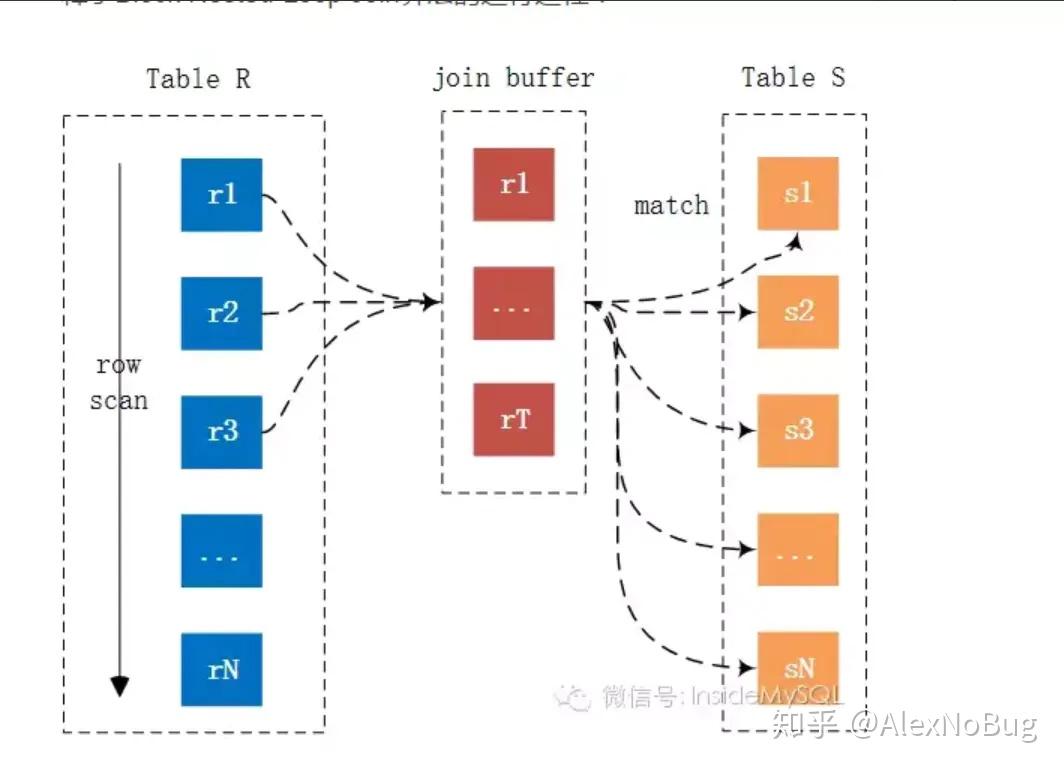
$Block\ Nested-Loop\ Join:$
如果有索引,会选取第二种方式进行join,但如果join列没有索引,就会采用$Block\ Nested-Loop\ Join$。可以看到中间有个$join\ buffer$缓冲区,是将驱动表的所有join相关的列(这里不仅仅指用来join的列,还包含select的列)都先缓存到join buffer中,然后批量与匹配表进行匹配,将第一种多次比较合并为一次,降低了非驱动表$S$的访问频率。默认情况下$join_buffer_size=256K$,在查找的时候$MySQL$会将所有的需要的列缓存到$join\ buffer$当中。在一个有N个JOIN关联的SQL当中会在执行时候分配N-1个$join\ buffer$。
具体做法如下:
- 先从表$R$中取出满足条件的数据,放入$join\ buffer$中
- 遍历表$S$,每次取出一条数据与$join\ buffer$中的数据进行关联字段的比较。满足条件的进入结果集
- 如果$join\ buffer$中一次性放不下所有满足条件的数据,那么以上两步需要重复进行